


Data flow testing is used to analyze the flow of data in the program. It is the process of collecting information about how the variables flow the data in the program. It tries to obtain particular information of each particular point in the process.
Data flow testing is a group of testing strategies to examine the control flow of programs in order to explore the sequence of variables according to the sequence of events. It mainly focuses on the points at which values assigned to the variables and the point at which these values are used by concentrating on both points, data flow can be tested.
Data flow testing uses the control flow graph to detect illogical things that can interrupt the flow of data. Anomalies in the flow of data are detected at the time of associations between values and variables due to:
- If the variables are used without initialization.
- If the initialized variables are not used at least once.
Let's understand this with an example:
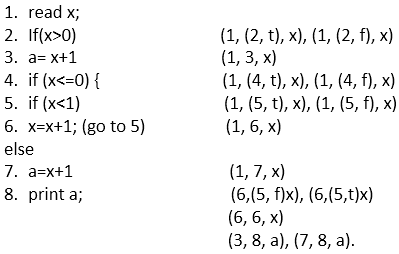
In this code, we have a total 8 statements, and we will choose a path which covers all the 8 statements. As it is evident in the code, we cannot cover all the statements in a single path because if statement 2 is true then statements 4, 5, 6, 7 not covered, and if statement 4 is true then statement 2 and 3 are not covered.
So, we are taking two paths to cover all the statements.
1. x= 1 Path - 1, 2, 3, 8
Output = 2
When we set value of x as 1 first it come on step 1 to read and assign the value of x (we took 1 in path) then come on statement 2 (x>0 (we took 2 in path)) which is true and it comes on statement 3 (a= x+1 (we took 3 in path)) at last it comes on statement 8 to print the value of x (output is 2).
For the second path, we take the value of x is 1
2. Set x= -1 Path = 1, 2, 4, 5, 6, 5, 6, 5, 7, 8
Output = 2
When we set the value of x as ?1 then first, it comes on step 1 to read and assign the value of x (we took 1 in the path) then come on step number 2 which is false because x is not greater than 0 (x>0 and their x=-1). Due to false condition, it will not come on statement 3 and directly jump on statement 4 (we took 4 in path) and 4 is true (x<=0 and their x is less than 0) then come on statement 5 (x<1 (we took 5 in path)) which is also true so it will come on statement 6 (x=x+1 (we took 6 in path)) and here x is incremented by 1.
So, x=-1+1
x=0
There is value of x become 0. Now it goes to statement 5(x<1 (we took 5 in path)) with value 0 and 0 is less than 1 so, it is true. Come on statement 6 (x=x+1 (we took 6 in path))
x=x+1 x= 0+1 x=1
There x has become 1 and again goes to statement 5 (x<1 (we took 5 in path)) and now 1 is not less than 1 so, condition is false and it will come to else part means statement 7 (a=x+1 where the value of x is 1) and assign the value to a (a=2). At last, it come on statement 8 and print the value (Output is 2).
Make associations for the code:
Associations
In associations we list down all the definitions with all of its uses.
(1, (2, f), x), (1, (2, t), x), (1, 3, x), (1, (4, t), x), (1, (4, f), x), (1, (5, t), x), (1, (5, f), x), (1, 6, x), (1, 7, x), (6,(5, f)x), (6,(5,t)x), (6, 6, x), (3, 8, a), (7, 8, a).
How to make associations in data flow testing <link>

- (1, (2, t), x), (1, (2, f), x)- This association is made with statement 1 (read x;) and statement 2 (If(x>0)) where x is defined at line number 1, and it is used at line number 2 so, x is the variable.
Statement 2 is logical, and it can be true or false that's why the association is defined in two ways; one is (1, (2, t), x) for true and another is (1, (2, f), x) for false. - (1, 3, x)- This association is made with statement 1 (read x;) and statement 3 (a= x+1) where x is defined in statement 1 and used in statement 3. It is a computation use.
- (1, (4, t), x), (1, (4, f), x)- This association is made with statement 1 (read x;) and statement 4 (If(x<=0)) where x is defined at line number 1 and it is used at line number 4 so x is the variable. Statement 4 is logical, and it can be true or false that's why the association is defined in two ways one is (1, (4, t), x) for true and another is (1, (4, f), x) for false.
- (1, (5, t), x), (1, (5, f), x)- This association is made with statement 1 (read x;) and statement 5 (if (x<1)) where x is defined at line number 1, and it is used at line number 5, so x is the variable.
Statement 5 is logical, and it can be true or false that's why the association is defined in two ways; one is (1, (5, t), x) for true and another is (1, (5, f), x) for false. - (1, 6, x)- This association is made with statement 1 (read x;) and statement 6 (x=x+1). x is defined in statement 1 and used in statement 6. It is a computation use.
- (1, 7, x)- This association is made with statement 1 (read x) and statement 7 (a=x+1). x is defined in statement 1 and used in statement 7 when statement 5 is false. It is a computation use.
- (6, (5, f) x), (6, (5, t) x)- This association is made with statement 6 (x=x+1;) and statement 5 if (x<1) because x is defined in statement 6 and used in statement 5. Statement 5 is logical, and it can be true or false that's why the association is defined in two ways one is (6, (5, f) x) for true and another is (6, (5, t) x) for false. It is a predicted use.
- (6, 6, x)- This association is made with statement 6 which is using the value of variable x and then defining the new value of x.
x=x+1
x= (-1+1)
Statement 6 is using the value of variable x that is ?1 and then defining new value of x [x= (-1+1) = 0] that is 0. - (3, 8, a)- This association is made with statement 3(a= x+1) and statement 8 where variable a is defined in statement 3 and used in statement 8.
- (7, 8, a)- This association is made with statement 7(a=x+1) and statement 8 where variable a is defined in statement 7 and used in statement 8.
Definition, c-use, p-use, c-use some p-use coverage, p-use some c-use coverage in data flow testing <link>
The next task is to group all the associations in Definition, c-use, p-use, c-use some p-use coverage, p-use some c-use coverage categories.
See the code below:
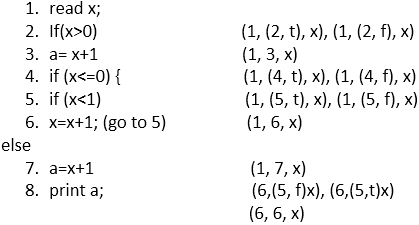
So, these are the all association which contain definition, Predicate use (p-use), Computation use (c-use)
(1, (2, f), x), (1, (2, t), x), (1, 3, x), (1, (4, t), x), (1, (4, f), x), (1, (5, t), x), (1, (5, f), x), (1, 6, x), (1, 7, x), (6,(5, f)x), (6,(5,t)x), (6, 6, x), (3, 8, a), (7, 8, a), (3, 8, a), (7, 8, a)
Definition
Definition of a variable is the occurrence of a variable when the value is bound to the variable. In the above code, the value gets bound in the first statement and then start to flow.
- If(x>0) is statement 2 in which value of x is bound with it.
Association of statement 2 is (1, (2, f), x), (1, (2, t.) - a= x+1 is statement 3 bounded with the value of x
Association of statement 3 is (1, 3, x)
All definitions coverage
(1, (2, f), x), (6, (5, f) x), (3, 8, a), (7, 8, a).
Predicate use (p-use)
If the value of a variable is used to decide an execution path is considered as predicate use (p-use). In control flow statements there are two
Statement 4 if (x<=0) is predicate use because it can be predicate as true or false. If it is true then if (x<1),6x=x+1; execution path will be executed otherwise, else path will be executed.
Computation use (c-use)
If the value of a variable is used to compute a value for output or for defining another variable.
Statement 3 a= x+1 (1, 3, x)
Statement 7 a=x+1 (1, 7, x)
Statement 8 print a (3, 8, a), (7, 8, a).
These are Computation use because the value of x is used to compute and value of a is used for output.
All c-use coverage
(1, 3, x), (1, 6, x), (1, 7, x), (6, 6, x), (6, 7, x), (3, 8, a), (7, 8, a).
All c-use some p-use coverage
(1, 3, x), (1, 6, x), (1, 7, x), (6, 6, x), (6, 7, x), (3, 8, a), (7, 8, a).
All p-use some c-use coverage
(1, (2, f), x), (1, (2, t), x), (1, (4, t), x), (1, (4, f), x), (1, (5, t), x), (1, (5, f), x), (6, (5, f), x), (6, (5, t), x), (3, 8, a), (7, 8, a).
After collecting these groups, (By examining each point whether the variable is used at least once or not) tester can see all statements and variables are used. The statements and variables which are not used but exist in the code, get eliminated from the code.
0 Comments