


Equivalence partitioning is a technique of software testing in which input data is divided into partitions of valid and invalid values, and it is mandatory that all partitions must exhibit the same behavior. If a condition of one partition is true, then the condition of another equal partition must also be true, and if a condition of one partition is false, then the condition of another equal partition must also be false. The principle of equivalence partitioning is, test cases should be designed to cover each partition at least once. Each value of every equal partition must exhibit the same behavior as other.
The equivalence partitions are derived from requirements and specifications of the software. The advantage of this approach is, it helps to reduce the time of testing due to a smaller number of test cases from infinite to finite. It is applicable at all levels of the testing process.
Examples of Equivalence Partitioning technique
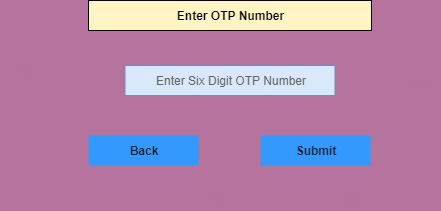
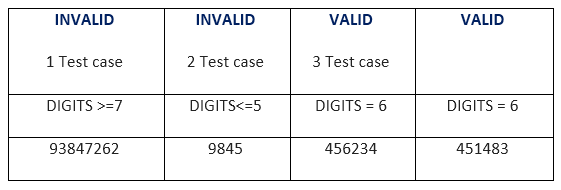
Assume that there is a function of a software application that accepts a particular number of digits, not greater and less than that particular number. For example, an OTP number which contains only six digits, less or more than six digits will not be accepted, and the application will redirect the user to the error page.
Let's see one more example.
A function of the software application accepts a 10 digit mobile number.
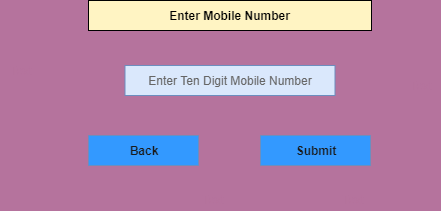
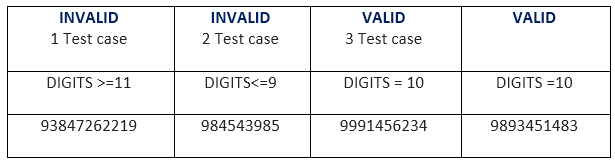
In both examples, we can see that there is a partition of two equally valid and invalid partitions, on applying valid value such as OTP of six digits in the first example and mobile number of 10 digits in the second example, both valid partitions behave same, i.e. redirected to the next page.
Another two partitions contain invalid values such as 5 or less than 5 and 7 or more than 7 digits in the first example and 9 or less than 9 and 11 or more than 11 digits in the second example, and on applying these invalid values, both invalid partitions behave same, i.e. redirected to the error page.
We can see in the example, there are only three test cases for each example and that is also the principal of equivalence partitioning which states that this method intended to reduce the number of test cases.
How we perform equivalence partitioning
We can perform equivalence partitioning in two ways which are as follows:
Let us see how pressman and general practice approaches are going to use in different conditions:
Condition1
If the requirement is a range of values, then derive the test case for one valid and two invalid inputs.
Here, the Range of values implies that whenever we want to identify the range values, we go for equivalence partitioning to achieve the minimum test coverage. And after that, we go for error guessing to achieve maximum test coverage.
According to pressman:
For example, the Amount of test field accepts a Range (100-400) of values:
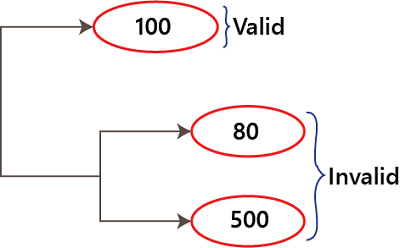
According to General Practice method:
Whenever the requirement is Range + criteria, then divide the Range into the internals and check for all these values.
For example:
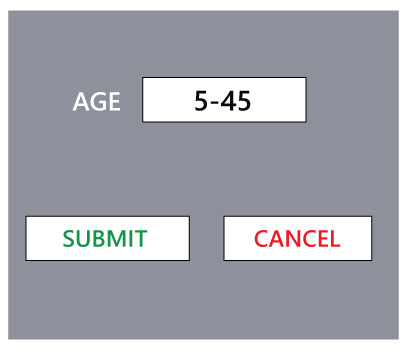
In the below image, the pressman technique is enough to test for an age text field for one valid and two invalids. But, if we have the condition for insurance of ten years and above are required and multiple policies for various age groups in the age text field, then we need to use the practice method.
Condition2
If the requirement is a set of values, then derive the test case for one valid and two invalid inputs.
Here, Set of values implies that whenever we have to test a set of values, we go for one positive and two negative inputs, then we moved for error guessing, and we also need to verify that all the sets of values are as per the requirement.
Example 1
Based on the Pressman Method
If the Amount Transfer is (100000-700000)
Then for, 1 lakh →Accept
And according to General Practice method
The Range + Percentage given to 1 lakh - 7 lakh
Like: 1lak - 3lak →5.60%
3lak - 6lak →3.66%
6lak - 7lak →Free

If we have things like loans, we should go for the general practice approach and separate the stuff into the intervals to achieve the minimum test coverage.
Example 2
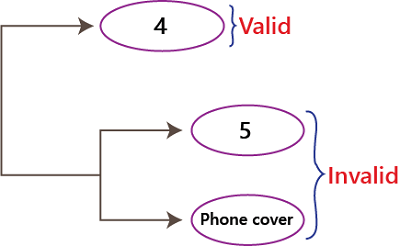
if we are doing online shopping, mobile phone product, and the different Product ID -1,4,7,9

Here, 1 → phone covers 4 → earphones 7 → charger 9 → Screen guard
And if we give the product id as 4, it will be accepted, and it is one valid value, and if we provide the product id as 5 and phone cover, it will not be accepted as per the requirement, and these are the two invalid values.
Condition 3
If the requirement id Boolean (true/false), then derive the test case for both true/false values.
The Boolean value can be true and false for the radio button, checkboxes.
For example
|
Serial no |
Description |
Input |
Expected |
Note |
|
1 |
Select valid |
NA |
True |
--- |
|
2 |
Select invalid |
NA |
False |
Values can be chaange
based according to the requirement. |
|
3 |
Do not select |
NA |
Do not select
anything, error message should be displayed |
We cannot go for
next question |
|
4 |
Select both |
NA |
We can select any
radio button |
Only one radio
button can be selected at a time. |
In Practice method, we will follow the below process:
Here, we are testing the application by deriving the below inputs values:

Let us see one program for our better understanding.
When the pressman technique is used, the first two conditions are tested, but if we use the practice method, all three conditions are covered.
We don't need to use the practice approach for all applications. Sometime we will use the pressman method also.
But, if the application has much precision, then we go for the practice method.
If we want to use the practice method, it should follow the below aspects:
- It should be product-specific
- It should be case-specific
- The number of divisions depends on the precision( 2% and 3 % deduction)
Advantages and disadvantages of Equivalence Partitioning technique
Following are pros and cons of equivalence partitioning
technique:
|
Advantagesa |
disadvantages |
|
It is
process-oriented |
All necessary inputs
may not cover. |
|
We can achieve the
Minimum test coverage |
This technique will
not consider the condition for boundary value analysis. |
|
It helps to decrease
the general test execution time and also reduce the set of test data. |
The test engineer
might assume that the output for all data set is right, which leads to the
problem during the testing process. |
0 Comments